Clustering in Fabric: What Actually Speeds Up Your Warehouse
- CrayonsandCoding
- Jun 11
- 3 min read
Data layout still matters in Microsoft Fabric, but the way you optimize it depends on whether you’re using Warehouse or Lakehouse. Many teams apply classic “clustering key + recluster job” guidance from other platforms and miss how Fabric actually works. This guide explains the practical, accurate approach for performance and scalability in Fabric.
Understanding How Fabric Organizes Data
In Fabric Warehouse, the platform is designed to handle much of the physical optimization for you. Fabric uses a unified query optimizer, distributed query processing, automatic scaling behavior, caching, and automatic compaction/statistics mechanisms to improve performance.
That means optimization in Warehouse is usually less about manually forcing physical data layout and more about:
Good schema design
Correct data types
Strong ingestion patterns
Statistics quality
Query pattern monitoring
A key point: partitioned tables are currently listed as not supported in Warehouse table features.
Warehouse vs. Lakehouse: Different Optimization Models
Fabric Warehouse (T-SQL-first analytics)
In Warehouse, your biggest wins typically come from:
Fact/dimension modeling patterns
Selecting appropriate data types and consistent join keys
Efficient ingestion with CTAS/COPY/pipelines
Keeping statistics current
Monitoring and tuning query workloads
Fabric Lakehouse (Spark + Delta tables)
In Lakehouse, Spark/Delta maintenance commands are central to layout optimization:
OPTIMIZE for compaction
OPTIMIZE ... ZORDER BY (...) for selective filter patterns
V-Order decisions for read-heavy scenarios
So, if you want explicit file-layout tuning, it is usually a Lakehouse Delta workflow, not a Warehouse reclustering workflow.
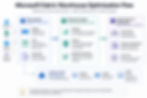
How to Optimize Fabric Warehouse in Practice
1. Model for analytics first
Design clear fact and dimension tables and avoid overloading wide tables with mixed semantics. This helps the optimizer generate better distributed plans.
2. Use ingestion methods that align with scale
Use CTAS, COPY INTO, pipelines, or dataflows based on your pipeline pattern. Bulk-friendly ingestion and predictable transforms reduce downstream query inefficiency.
3. Treat statistics as a performance feature
Fabric supports automatic statistics creation/refresh at query time, and you can also create/update statistics manually where needed. For heavily filtered/joined columns, statistics quality is critical.
4. Monitor before changing design
Use Data Warehouse Monitor, Query Insights, DMVs, and capacity metrics to identify real bottlenecks instead of guessing. Measure query behavior over time, not just first-run cold-cache behavior.
5. Use Lakehouse optimization for Spark-written Delta data
If your upstream writes come from Spark and are consumed by SQL analytics endpoint or Warehouse, apply compaction and Delta optimization patterns where appropriate.
Example: Improving Sales Reporting Responsiveness
Imagine reports are frequently filtered by StoreID and TransactionDate and have become slow in Fabric Warehouse.
A reliable optimization path is:
Validate star-schema alignment and join paths.
Confirm data type parity on join/filter columns.
Check auto/manual statistics coverage and freshness.
Review Query Insights for expensive operations.
Refine ingestion/transformation patterns if fragmentation or skew appears.
This approach is usually more effective in Fabric Warehouse than trying to apply unsupported or legacy-style manual partition/clustering strategies.
Best Practices Checklist
Optimize by workload evidence, not assumptions.
Prioritize schema, statistics, and ingestion consistency in Warehouse.
Use Spark Delta maintenance (OPTIMIZE, ZORDER, V-Order choices) in Lakehouse where explicit layout tuning is needed.
Reassess periodically as Fabric features evolve.
Summary
In Microsoft Fabric, “clustering” is not one universal knob. For Warehouse, focus on modeling, ingestion strategy, statistics, and monitoring For Lakehouse, use Spark/Delta optimization commands for explicit layout control.
Using the right model for the right engine gives you faster queries, lower operational overhead, and a more scalable data platform.
